
13
Esbozo de implementación ( ¿Procesos bloqueados? )
espLapso => Muy parecido a preparados, sólo que es necesario indicar cuándo despertarles o cuánto falta para despertarles, …
(Gp:) 1
(Gp:) 2
(Gp:) 3
(Gp:) 4
(Gp:) 97
(Gp:) 98
(Gp:) 99
(Gp:) 100
(Gp:) 50
(Gp:) type descriptorProceso is
record
pid: NATURAL;
estado: unEstado;
sig: idProceso;
lapso: NATURAL;
end record;
espLapso : unaCola;
(Gp:) 10
(Gp:) 5
(Gp:) 25
El campo sig me sigue sirviendo para encadenar
Otras formas de implementarlo:
(Gp:) 5
(Gp:) 5
(Gp:) 15
(Gp:) 4
(Gp:) 50
(Gp:) 97

14
Esbozo de implementación ( ¿Procesos bloqueados? )
espFinHijo => El fin de un hijo sólo puede estar esperándolo su Padre. Puede no ser necesaria una cola.
type descriptorProceso is
record
pid: NATURAL;
padre: idProceso;
estado: unEstado;
sig: idProceso;
lapso: NATURAL;
end record;
El Padre (P) hace wait (H):
— Localizar H en procesos => h
if h.estado = zombie then
Liberar recursos del Hijo y
continuar al Padre
else — hijo vivo
p.estado:=espFinHijo; p.sig:=h;
liberar CPU;
Un Hijo(H) termina exit:
If (p.estado = espFinHijo) & (p.sig = h) then
liberar recursos Hijo y continuar Padre
else
h.estado := zombie y liberar CPU

15
Esbozo de implementación ( Concluyendo )
maxProcesos : constant := 100;
type idProceso is NATURAL range 0..maxProcesos;
type unEstado is (ejecutandose, preparado,
espLapso, espFinHijo, zombie);
type descriptorProceso is
record
pid: NATURAL;
padre: idProceso;
estado: unEstado;
sig: idProceso;
lapso: NATURAL;
SP: address;
memoria: ———-;
ficheros: ———-;
tiempos: ———-;
end record;
type unaCola is
record
primero: idProceso := 0;
ultimo: idProceso := 0;
end record;
procesos : array [1..maxProcesos] of
descriptorProceso;
ejecutandose: idProceso;
preparados, espLapso: unaCola;
¿ fork y exec ?

16
Campos en una entrada a la tabla de procesos
Esbozo de implementación ( Otro ejemplo )

17
Esbozo de implementación ( El Cambio de Contexto )
Causas?
(Gp:) Llamada al Sistema
Fin de Proceso
Bien/Mal
Interrupción
(Gp:) Trap
(Gp:) (E/S, F.R.)
(Gp:) Mecanismo similar
Supongamos como causa "Fin de Rodaja"
(Gp:) ejecu-
tándose
(Gp:) Pi
(Gp:) Hw
(Gp:) (1)
(1) Reconocimiento de la interrupción
(Gp:) S.O.
(Gp:) Pj
(Gp:) Ens.
(Gp:) (2)
(2) Salvar reg (Pi) y conmutar de pila
(Gp:) C/Modula/Ada
(Gp:) (3)
(3) 1 Recorrer dormitorio
2 Elegir siguiente proceso
(Gp:) Ens.
(Gp:) (4)
(4) Recuperar reg (Pj) y cederle control
(Gp:) Planificador
(Gp:) Dispatcher
¿No hay procesos preparados?

18
(Gp:) Vector de Interrupciones
(Gp:) S.O.
Esbozo de implementación ( El Cambio de Contexto )
———-
———-
sleep(10)
———-
———-
exit(0)
——-
——-
——-
——-
——-
——-
——-
——-
——-
——-
——-
——-
(Gp:) TRAP #0
——-
——-
——-
——-
——-
(Gp:) INT 3
———-
divu d5,d0
———-
——-
——-
——-
——-
——-
(Gp:) DIV 0
(Gp:) Se salva el SR y PC
(Gp:) ——-
——-
——-
——-
——-
——-
——-
——-
(Gp:) Cambio de contexto

19
Threads ( Visión abstracta )
Modelo de procesos más común ? Espacios de direcciones disjuntos
(Gp:) Registros
Código
Datos, Pila
Ficheros
(Gp:) Pi
(Gp:) Registros
Código
Datos, Pila
Ficheros
(Gp:) Pj
(Gp:) fork
(Gp:) exec
(Gp:) ls.exe
Facilita protección Pi?Pj, pero:
Creación laboriosa
Cambio de contexto pesado
(procesador + entorno) TLB's, cachés, …
Comunicación vía mensajes
más seguro pero más lento
¿Y si los procesos son cooperantes?
Objetivo común
Colaboración vs agresión
Protección más laxa
Pueden desear mantener datos comunes con los menores costes de tiempo

20
(Gp:) BD utilidades
Threads ( Visión abstracta )
Procesos Ligeros ? Espacios de direcciones no disjuntos
(Gp:) Registros
Pila
(Gp:) Registros
Pila
(Gp:) Código, Datos
Ficheros
(Gp:) Ti
(Gp:) Tj
Servidor de localización de utilidades
(Gp:) C1
(Gp:) C2
(Gp:) Cn
(Gp:) S
(Gp:) consulta
(Gp:) alta
(Gp:) consulta
(Gp:) petición
respuesta
(Gp:) petición
(Gp:) petición
¡ Muy eficaz con multiprocesadores !
Soportados de dos formas:
En el espacio del S.O.
En el espacio del Usuario
Biblioteca

21
Threads ( "Linux" )
int __clone (int (*fn) (void *arg), void *child_stack, int flags, void *arg)
(Gp:) Como fork sólo que crea un Thread "Específico de Linux"
Thread soportado como tal por el S.O. (no portable)
(Gp:) Biblioteca pthread (API POSIX 1003.1c)
int pthread_create (pthread_t * thread, atributos, funcion, argumentos)
pthread_t pthread_self (void)
int pthread_exit (void *estado)
int pthread_join (pthread_t thread, void **estado)
……………………………………………
……………………………………………
¿ fork + threads ?

22
Threads ( Ejemplos de uso: tonto.c )
#include < pthread.h>
#include < stdio.h>
int main (int argc, char *argv[]){
pthread_t tA, tB;
int datoA=0; datoB=0;
pthread_create(&tA, NULL, A, NULL);
pthread_create(&tB, NULL, B, NULL);
pthread_join (tA, NULL);
pthread_join (tB, NULL);
exit (0);
}
void *B (void *basura) {
datoB = 2000;
sleep (5);
printf ("datoA=%dn", datoA);
pthread_exit (NULL);
}
void *A (void *basura) {
datoA = 1000;
sleep (5);
printf ("datoB=%dn", datoB);
pthread_exit (NULL);
}
(Gp:) datoC=0;
(Gp:) int datoC;
(Gp:) int datoC;
(Gp:) ?

Threads ( Ejemplos de uso: cuentaPar.c )
cuentaPar.c: Número de apariciones de un número en un vector
(Gp:) 6 2 0 7 4 9 3 4 9 8 0 6 7 9 6 0 6 7 9 8 6 2 5 2 6 4 7 9 3 5 2 1 7 3 2 6 6 4 4 0
(Gp:) const
N = 40;
objetivo = 6;
numCPUs = 4;
var
vector array[1..N] of integer;
¿ Algoritmo paralelo ?
(Gp:) T0
(Gp:) T1
(Gp:) T2
(Gp:) T3
(Gp:) 1
(Gp:) 3
(Gp:) 2
(Gp:) 2
(Gp:) +
(Gp:) 8
23

(Gp:)
int longRodaja, numVecesLocal[MAX_ESCLAVOS], *vector;
void *esclavo (void *parametro) { ….. }
int main (int argc, char *argv[]) {
int i, numVeces, cardinalidad = atoi (argv[1]);
int numEsclavos = atoi (argv[2]);
pthread_t pids[MAX_ESCLAVOS];
// Pedir memoria e inicializar vector
// Crear esclavos y esperar a que terminen su trabajo
for (i = 0; i < numEsclavos; i++)
pthread_create (&pids[i], NULL, esclavo, (void *) i);
for (i = 0; i < numEsclavos; i++)
pthread_join (pids[i], NULL);
// Sumar los valores de todos e informar del resultado
numVeces = numVecesLocal[0];
for (i = 1; i < numEsclavos; i++)
numVeces = numVeces + numVecesLocal[i];
printf ("Veces que aparece = %dn", numVeces);
}
(Gp:) %cuentaPar 1000000 4
Threads ( Ejemplos de uso: cuentaPar.c )
24

// Variables globales
int longRodaja, numVecesLocal[MAX_ESCLAVOS], *vector;
void *esclavo (void *parametro) {
int yo, inicio, fin, i, j, numVeces;
yo = (int) parametro;
inicio = yo * longRodaja;
fin = inicio + longRodaja;
// Buscar en mi parte del vector
numVeces = 0;
for (i = inicio, i < fin; i++)
if (vector[i] == NUM_BUSCADO) numVeces++;
numVecesLocal[yo] = numVeces;
pthread_exit (NULL);
}
25
Threads ( Ejemplos de uso: cuentaPar.c )

(Gp:) 5
(Gp:) 1,286
(Gp:) 4,26
(Gp:) 0,85
(Gp:) 6
(Gp:) 1,127
(Gp:) 4,86
(Gp:) 0,81
(Gp:) 7
(Gp:) 1,113
(Gp:) 4,92
(Gp:) 0,70
(Gp:) 8
(Gp:) 0,998
(Gp:) 5,49
(Gp:) 0,69
(Gp:) cuentaPar 400.000.000 1..8 // Recorriéndolo diez veces
(Gp:) 2 Xeon E5520 Quad
2,26GHz . 8ML3 . 12GB . 500GB
Threads ( Ejemplos de uso: cuentaPar.c )
26
(Gp:) Esclavos
(Gp:) Tiempo
(Gp:) Aceleración
(Gp:) Eficiencia
(Gp:) 1
(Gp:) 5,480
(Gp:) 2
(Gp:) 2,721
(Gp:) 2,01
(Gp:) 1,01
(Gp:) 4
(Gp:) 1,408
(Gp:) 3,89
(Gp:) 0,97
(Gp:) An = T1 / Tn
(Gp:) En = An / n

sortPar.c: Ordenar un vector en memoria
(Gp:) 3 8 15 2 4 1 7 10 6 14 13 5 11 9 12 16
(Gp:) T0
(Gp:) T1
(Gp:) T2
(Gp:) T3
(Gp:) 2 3 8 15 1 4 7 10 5 6 13 14 9 11 12 16
(Gp:) ordenar
(Gp:) 1 2 3 4 7 8 10 15 5 6 9 11 12 13 14 16
(Gp:) T0
(Gp:) T2
(Gp:) mezclar
(Gp:) T0
(Gp:) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
(Gp:) mezclar
Threads ( Ejemplos de uso: sortPar.c )
27

sortPar.c: Ordenar un vector en memoria [Refinamiento]
(Gp:) A
(Gp:) B
(Gp:) C
(Gp:) D
(Gp:) E
(Gp:) F
(Gp:) G
(Gp:) 0
(Gp:) 1
(Gp:) 2
(Gp:) 3
(Gp:) 0
(Gp:) 2
(Gp:) 0
esclavo (yo: integer);
ordenarRodaja(yo);
case yo of
0: mezclar(A,B,E); mezclar(E,F,G);
1: ;
2: mezclar(C,D,F);
3: ;
end;
?
(Gp:) La mezcla es destructiva => vector auxiliar
(Gp:) Va
(Gp:) Va
(Gp:) Vb
(Gp:) Va
Mezclar requiere haber ordenado . => semáforos
Threads ( Ejemplos de uso: sortPar.c )
28
sem_init
sem_wait
sem_post

#define MAX_ENTERO 10000
#define MAX_ESCLAVOS 4 // Solo funciona con 4 esclavos
//————– VARIABLES GLOBALES ——————————-
int cardinalidad, longRodaja;
int *vector, *vectorBis;
sem_t S1a0, S3a2, S2a0;
void imprimir (int *vector) {
int i;
printf ("Contenido del vectorn");
printf ("====================n");
for (i=0; i< cardinalidad; i++) {
printf ("%6d ", vector[i]);
if ((i%10) == 0) printf ("n");
}
printf ("n");
}
void mezclar (int i, int longRodaja, int *vOrg, int *vDst) {
int iDst, iTope, j, jTope;
iTope = i + longRodaja;
j = iTope;
jTope = j + longRodaja;
for (iDst = i; iDst < jTope; iDst++) {
if (i == iTope ) vDst[iDst] = vOrg[j++];
else if (j == jTope ) vDst[iDst] = vOrg[i++];
else if (vOrg[i] < vOrg[j]) vDst[iDst] = vOrg[i++];
else vDst[iDst] = vOrg[j++];
}
}
Threads ( Ejemplos de uso: sortPar.c )
29

void *esclavo(void *parametro) {
int yo, inicio, fin, i, j, imenor, menor;
int unCuarto, unMedio;
yo = (int) parametro;
inicio = yo * longRodaja;
fin = inicio + longRodaja;
unMedio = cardinalidad / 2;
unCuarto = cardinalidad / 4;
// Ordenar por insercion directa
for (i = inicio; i < fin; i++) {
imenor = i; menor = vector[i];
for (j = i; j < fin; j++)
if (vector[j] < menor) {
imenor = j; menor = vector[j];
}
vector[imenor] = vector[i];
vector[i] = menor;
}
// Fase de mezclas. Solo valida para 4 esclavos
switch (yo) {
case 0: sem_wait (&S1a0); mezclar(0, unCuarto, vector, vectorBis);
sem_wait (&S2a0); mezclar(0, unMedio, vectorBis, vector);
break;
case 1: sem_post (&S1a0); break;
case 2: sem_wait (&S3a2); mezclar(unMedio, unCuarto, vector, vectorBis);
sem_post (&S2a0); break;
case 3: sem_post (&S3a2); break;
default: printf ("Errorn"); break;
}
pthread_exit(NULL);
}
Threads ( Ejemplos de uso: sortPar.c )
30

int main( int argc, char *argv[] ) {
int i, numEsclavos;
pthread_t pids[MAX_ESCLAVOS];
cardinalidad = atoi(argv[1]);
numEsclavos = MAX_ESCLAVOS;
longRodaja = cardinalidad / numEsclavos;
// Pedir memoria e inicializar el vector
vector = malloc(cardinalidad * sizeof(int));
vectorBis = malloc(cardinalidad * sizeof(int));
for (i=0; i< cardinalidad; i++)
vector[i] = random() % MAX_ENTERO;
imprimir(vector);
// Inicializar semaforos para sincronizar
sem_init (&S1a0, 0, 0);
sem_init (&S3a2, 0, 0);
sem_init (&S2a0, 0, 0);
// Crear esclavos y esperar a que terminen su trabajo
for (i=0; i< numEsclavos; i++)
pthread_create (&pids[i], NULL, esclavo, (void *) i);
for (i=0; i< numEsclavos; i++)
pthread_join (pids[i], NULL);
imprimir(vector);
return (0);
}
sort 200000 => 8:350
sortPar 200000 => 2:100
Threads ( Ejemplos de uso: sortPar.c )
31

32
pthread_create pthread_join
pthread_exit pthread_self
Threads ( En el espacio de usuario )
(Gp:) El S.O. no los soporta
Cambio contexto rápido
Distintos planificadores
(Gp:) read, . ¡ Bloqueantes !
Falta de página
¡Planificación expulsora!

33
Threads ( En el espacio del S.O. )
(Gp:) ?

34
Comunicación entre Procesos
Los procesos cooperantes necesitan mecanismos para sincronizarse y comunicarse información de forma segura
Sincronización ? Ordenación temporal de la ejecución de procesos
A antes que B
(Gp:) Canal de Panamá
Tortilla de patatas
Batir Pelar Pelar
Huevos Cebollas Patatas
Mezclar, Añadir Sal y Freir
Comunicación ? Paso de información entre tareas
Síncrona o Asíncrona
Filtros Unix:
who | wc | sed -e 's/ [ ]*/:/g' | cut -d: -f2

35
Condiciones de Carrera
La falta de sincronismo entre procesos cooperantes da problemas
Canal de Panamá ? Barco encallado
Tortilla de Patatas ? No hay quien se la coma
Uso de datos / recursos comunes ? Inconsistencia
El empresario y los taxistas:
(Gp:) ¡Que buen negocio!
(Gp:) ¡Me tangan!

36
Condiciones de Carrera (Modelización con threads)
Ingreso de Taxista 1 = 80729
Ingreso de Taxista 2 = 80618
Total recaudacion = 161096
(Gp:) +
(Gp:) 161347
(Gp:) int cuenta;
void *taxista(void *parametro) { ….. }
int main( int argc, char *argv[] ) {
int i, numEsclavos;
pthread_t pids[MAX_ESCLAVOS];
numEsclavos = atoi(argv[1]);
cuenta = 0;
// Crear esclavos y esperar a que terminen su trabajo
for (i=0; i< numEsclavos; i++)
pthread_create (&pids[i], NULL, taxista, (void *) i);
for (i=0; i< numEsclavos; i++)
pthread_join (pids[i], NULL);
printf ("Total recaudacion = %dn", cuenta);
return (0);
}

37
(Gp:) Ingreso
Condiciones de Carrera (Modelización con threads)
void *taxista (void *parametro) {
// Variables
recaudacion = 0; mio = 0;
do {
espera = random() % MAX_ESPERA;
for (i=1; i< espera; i++);
importe := random (maxImporte);
mio := mio + (importe / RATIO_TAXISTA);
cuenta := cuenta + importe –
(importe / RATIO_TAXISTA);
recaudacion := recaudacion + importe;
} while (mio < SUELDO_DIA);
printf ("Ingreso de Taxista %d = %dn",
yo, recaudacion – mio);
pthread_exit (NULL);
}
(Gp:) Hacer Carrera
(Gp:) Buscar Cliente

38
Condiciones de Carrera (Modelización con threads)
(Gp:) Threads
(Gp:) pc1:4Cores
(Gp:) pc9:8Cores
(Gp:) 2
(Gp:) 4
(Gp:) 8
(Gp:) 16
(Gp:) 32
(Gp:) Fallos x 1.000
(Gp:) 7
(Gp:) 64
(Gp:) 230
(Gp:) 533
(Gp:) 830
(Gp:) 207
(Gp:) 926
(Gp:) 1.000
(Gp:) 1.000
(Gp:) 1.000

39
3: cuenta := cuenta + importe
Condiciones de Carrera (El problema)
(Gp:) 3.1: PUSH importe
3.2: PUSH cuenta
3.3: ADDP
3.4: POP cuenta
3.1, 3.2
(Gp:) T1
(Gp:) T2
(Gp:) 5.000
(Gp:) cuenta
(Gp:) 10.000
(Gp:) T1.importe
(Gp:) 3.3
(Gp:) 5.000
(Gp:) 10.000
(Gp:) T1.SP
3.1, 3.2
(Gp:) 1.500
(Gp:) T2.importe
(Gp:) 3.3
(Gp:) 5.000
(Gp:) 1.500
(Gp:) T2.SP
3.3, 3.4
(Gp:) 15.000
(Gp:) 15.000
(Gp:) cuenta
3.3, 3.4
(Gp:) 6.500
(Gp:) cuenta
(Gp:) 6.500
¿problema?

40
Exclusión mutua y Región crítica (La solución)
(Gp:) RC
(Gp:) RC
(Gp:) Aquí como
máximo un Pi
(Gp:) Exclusión
Mutua
(Gp:) Integridad Datos Comunes
(Gp:) Aquí cero,
uno o más Pi
Los Pi indicarán cuándo EntranEnRC y cuándo SalenDeRC

41
Exclusión mutua y Región crítica (La solución)
EntrarEnRC;
cuenta := cuenta + importe –
(importe div ratioTaxista);
SalirDeRC;
REQUISITOS
En una misma Región Crítica no más de un proceso
Sin supuestos: #µP, #Pi, velocidades relativas, …..
Ningún Pi fuera de su Región Crítica bloqueará a otros Pj
Decisión de quién entra a una Región Crítica en un tiempo finito

42
Implementación de la Exclusión Mutua
Mecanismos:
Inhibición de interrupciones . Semáforos
Cerrojos (espera activa) . Monitores
(Gp:) Hw
(Gp:) Sw
(Gp:) Lenguaje
(Gp:) S.O.
Inhibición de interrupciones
Taxistas
InhibirInterrupciones
cuenta := cuenta + importe
PermitirInterrupciones
RC muy corta o pueden
perderse interrupciones
Exclusión total vs parcial
DirecciónGeneralDeTráfico
repeat
aguardarAgazapados y ¡foto!
InhibirInterrupciones
numeroMultas++
PermitirInterrupciones
until cubiertoCupo
Sólo válido en monoprocesador
Peligroso en manos del usuario
Útil dentro del propio S.O.

43
Implementación de la Exclusión Mutua ( Cerrojos )
Una variable "cerrojo" por cada RC distinta que indica Libre/Ocupada
(Gp:) Taxistas
Entrar (RCTaxistas)
cuenta := cuenta + importe
Salir (RCTaxistas)
(Gp:) Guardia Civil
Entrar (RCDGT)
numeroMultas++
Salir (RCDGT)
(Gp:) while RCT = ocupada do null;
RCT := ocupada
cuenta := cuenta + importe;
RCT := libre
(Gp:) entrar tst.b RCT
bnz entrar
move.b #$FF,RCT
push importe
push cuenta
addp
pop cuenta
salir move.b #$00,RCT
RCT dc.b 0
¡ No funciona !

44
Implementación de la Exclusión Mutua ( El cerrojo falla )
(Gp:) T1
(Gp:) T2
(Gp:) 00
(Gp:) RCT
—————-
—————-
entrar tst.b RCT
—————-
—————-
tst.b RCT
bnz entrar
move.b #$FF,RCT
—————-
—————-
(Gp:) T1.SR
(Gp:) Z
(Gp:) 1
(Gp:) FF
(Gp:) RCT
(Gp:) T2 dentro RCT
bnz entrar
move.b #$FF,RCT
—————-
—————-
—————-
—————-
(Gp:) FF
(Gp:) RCT
¡¡ T1 también dentro RCT !!

45
Implementación de la Exclusión Mutua ( Un cerrojo seguro? )
(Gp:) El Hw ayuda con una instrucción atómica que consulta y cambia valor
(Gp:) tas.b cerrojo, valor
(Gp:) tst.b cerrojo
move.b valor,cerrojo
Algoritmos: Dekker, Dijkstra, Knuth, Peterson, …….
(Gp:) entrar tas.b RCT,#$FF
bnz entrar
push importe
push cuenta
addp
pop cuenta
salir move.b #$00,RCT
RCT dc.b 0
(Gp:) F.R.
¿Habrá problemas?
(Gp:) No funciona en multiprocesador ya que TAS es ininterrumpible dentro de un procesador, pero supone dos accesos al bus:
1 Lectura del cerrojo
2 Modificación del cerrojo
(Gp:) ¡SI!

46
Implementación de la Exclusión Mutua ( Un cerrojo seguro! )
T1
T2
(Gp:) 00
(Gp:) RCT
—————-
—————-
tas.b RCT,#$FF
—————-
—————-
tas.b RCT,#$FF
bnz entrar
(Gp:) T1.SR
(Gp:) Z
(Gp:) 1
(Gp:) FF
(Gp:) RCT
(Gp:) FF
(Gp:) RCT
bnz entrar
————-
————-
————-
————-
T1 en RCT
(Gp:) FF
(Gp:) RCT
T2 no puede
entrar en RC
mientras está T1
(Gp:) tas.b RCT,#$FF
bnz entrar

47
Implementación de la Exclusión Mutua ( TAS todavía falla! )
TAS ? PedirBus, Leer, PedirBus, Escribir
(Gp:) ?P1 ? T1 PB, L1, PB, E1
(Gp:) ?P2 ? T2 PB, L2, PB, E2
(Gp:) ???
(Gp:) ?P1
(Gp:) ?P2
(Gp:) RCT
(Gp:) L1, E1, L2, E2
T1 T2
(Gp:) L2, E2, L1, E1
T2 T1
(Gp:) L1, L2, E1, E2
T1 T2
tas.b RCT,#$FF
bnz entrar
(Gp:) PH
tasl.b RCT,#$FF
bnz entrar
———————
———————
¡ Todavía dos problemas !
Espera Activa
Inversión de prioridades
(Gp:) PL
(Gp:) deadLock
¿ Qué hacer ?
(Gp:) TASL "TAS with Lock" ? BusLock, Leer, Escribir, BusRelease
(Gp:) ( El Hw nos ayuda )
48
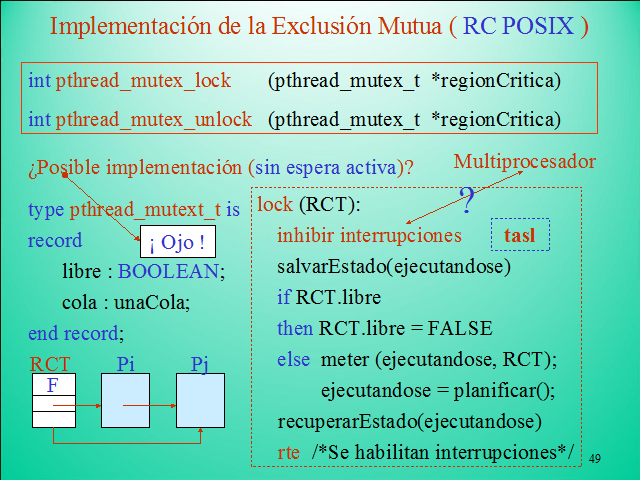
Implementación de la Exclusión Mutua ( RC POSIX )
int pthread_mutex_lock (pthread_mutex_t *regionCritica)
int pthread_mutex_unlock (pthread_mutex_t *regionCritica)
¿Posible implementación (sin espera activa)?
type pthread_mutext_t is
record
libre : BOOLEAN;
cola : unaCola;
end record;
(Gp:) F
(Gp:) RCT
(Gp:) Pi
(Gp:) Pj
lock (RCT):
inhibir interrupciones
salvarEstado(ejecutandose)
if RCT.libre
then RCT.libre = FALSE
else meter (ejecutandose, RCT);
ejecutandose = planificar();
recuperarEstado(ejecutandose)
rte /*Se habilitan interrupciones*/
(Gp:) Multiprocesador
(Gp:) ?
tasl
(Gp:) ¡ Ojo !

49
Implementación de la Exclusión Mutua ( Semáforos )
Soportado por el S.O. garantiza exclusión mutua sin espera activa
type Semaforos is private;
Inicializar (S: Semaforos; Valor: NATURAL);
Bajar (S); — Puede bloquear al proceso (Si Valor = 0)
Subir (S); — Puede desbloquear a UN proceso
(Gp:) Operaciones
Atómicas
Dar soporte a RC con semáforos es fácil:
Inicializar (S_RCT, 1) Inicializar (S_RCGC, 1)
————— —————
Bajar (S_RCT) Bajar (S_RCGC)
Cuenta := Cuenta + Importe numeroMultas++
Subir (S_RCT) Subir (S_RCGC)
————— —————

50
Implementación de la Exclusión Mutua ( Semáforos )
Precisando la semántica:
P.Bajar (S) ? IF Valor(S) > 0 THEN
Valor (P.Bajar(S)) = Valor(S) – 1
ELSE
P deja UCP y se bloquea esperando P'.Subir(S)
P.Subir(S) ? IF Hay_algun_Pi_esperando_en (S) THEN
Sacar a uno de ellos de espera
INDETERMINISMO
Proceso continuado
Proceso que coge UCP
JUSTICIA
ELSE
Valor (P.Subir(S)) = Valor (S) + 1

51
Implementación de la Exclusión Mutua ( Semáforos )
private type Semaforos is record
valor : NATURAL;
cola : unaCola;
end record;
procedure Inicializar (S : out Semaforos;
valor : NATURAL) is
begin
S.valor := valor;
end Inicializar;
Esbozo de implementación:
(Gp:) 0
(Gp:) S
(Gp:) Pi
(Gp:) Pk
(Gp:) Pj
(Gp:) ¿Dónde están los semáforos?
Hacen falta operaciones del estilo: crear, conectarse, destruir
(Gp:) Exclusión mutua, Salvado estado Pi
(Gp:) Dispatcher

52
Implementación de la Exclusión Mutua ( Semáforos )
procedure Bajar (S: in out Semaforos) is begin
if S.valor = 0 then
encolar (ejecutandose, S.cola);
planificar;
else S.valor := S.valor – 1; endif;
end Bajar;
procedure Subir (S: in out Semaforos) is begin
if S.cola.primero /= 0 then
encolar (sacarProceso(S.cola), preparados);
planificar;
else S.valor := S.valor + 1; endif;
end Subir;

53
Implementación de la Exclusión Mutua ( Semáforos POSIX )
int sem_init (sem_t *S, int global, unsigned int valor)
int sem_wait (sem_t *S)
int sem_post (sem_t *S)
int sem_destroy (sem_t *S)

54
Paso de mensajes
Debilidades del Sincronismo + Memoria Común:
Primitivas de bajo nivel (Inhibir Interrupciones, TASL, Semáforos)
Inviable en sistemas débilmente acoplados sin memoria común
(Gp:) Solución: Envío y recepción de mensajes
(Gp:) Porg
(Gp:) Pdst
(Gp:) Enviar (Pdst, msj)
(Gp:) Recibir (Porg, msj)
—–
—–
—–
(Gp:) Escribe
11
—–
—–
—–
—–
—–
—–
11
(Gp:) Lee
Primera aproximación a la sintaxis:
void enviar ( int Pdestino, void recibir ( int Porigen,
char * msj ); char * msj );
¿Puede fallar enviar/recibir?
(Gp:) ?
(Gp:) ?
(Gp:) int
(Gp:) int

Paso de mensajes ( Ejemplos de uso: cuentaParMsj.c )
¿Cómo podría ser cuentaPar.c si no hay memoria común?
(Gp:) 1
(Gp:) 3
(Gp:) 2
(Gp:) 2
(Gp:) 6 2 0 .
(Gp:) 0 6 7 .
(Gp:) 6 2 5 .
(Gp:) 2 1 7 .
(Gp:) +
(Gp:) 8
(Gp:) esclavo1
(Gp:) esclavo2
(Gp:) esclavo3
(Gp:) esclavo4
(Gp:) maestro
(Gp:) 6 2 0 .
(Gp:) 0 6 7 .
(Gp:) 6 2 5 .
(Gp:) 2 1 7 .
(Gp:) El vector lo tiene un proceso "maestro"
El maestro: reparte "envía" trabajo a los "esclavos" y
recoge "recibe" resultados
(Gp:) 6 2 0 .
(Gp:) 0 6 7 .
(Gp:) 6 2 5 .
(Gp:) 2 1 7 .
(Gp:) 1
(Gp:) 3
(Gp:) 2
(Gp:) 2
55

56
Paso de mensajes ( Ejemplos de uso: cuentaParMsj.c )
(Gp:) #define longRodaja (N/4)
int vector[N], iRodaja;
int veces, vecesLocal;
// Repartir trabajo
iRodaja = 0;
for e in 1..4 {
enviar (e, &vector[iRodaja],
longRodaja);
iRodaja += longRodaja;
}
// Recoger resultados
veces = 0;
for e in 1..4 {
recibir (e, &vecesLocal, 1);
veces += vecesLocal;
}
(Gp:) #define longRodaja (N/4)
int rodaja[longRodaja];
int veces;
recibir (0, rodaja,
longRodaja);
veces = contarEn (rodaja);
enviar (0, &veces, 1);
(Gp:) maestro
(Gp:) esclavo

57
Paso de mensajes (muchas semánticas)
(Gp:) —–
—–
—–
(Gp:) rec (Po, msj)
(Gp:) —–
—–
—–
(Gp:) —–
—–
—–
(Gp:) env (Pd, msj)
(Gp:) —–
—–
—–
(Gp:) Pd
¿Bloqueo?
(Gp:) El bloqueo dependerá de la ? | ? de mensajes
? msj ? Se le entrega a Pd y continua
(Gp:) ? msj ? Se bloquea a Pd hasta
(Gp:) No siempre
(Gp:) Tiempo Real
Tolerancia a Fallos
Bloquear
Bloquear un máximo
No Bloquear
(Gp:) int recibir ( int Porg, char * msj,
int TmaxEsp)
?
7
(Gp:) 0
(Gp:) ?
(Gp:) ?
(Gp:) Po
¿Bloqueo?
(Gp:) ¿Recibió Pd?
(Gp:) Po
Independencia del enlace de comunicación

58
Paso de mensajes (Cuestiones de Diseño)
Mensajes de longitud fija vs variable
Capacidad de almacenamiento 0 .. ?
Envío por copia vs referencia
Comunicación Directa vs Indirecta
(Gp:) Pi B Pj
(Gp:) Pi Pj
(Gp:) Simétrica vs Asimétrica
(Gp:) Unidireccional vs Bidireccional

59
Paso de mensajes (Mensajes de longitud fija vs variable)
Longitud Fija
El S.O. siempre envía el total
(Gp:) La aplicación distingue distintos msj.
Simplifica la gestión de la capacidad de almacenamiento del canal
Longitud Variable
El S.O. envía lo que diga la aplicación
(Gp:) ¿Cómo?
(Gp:) 110
(Gp:) Mensaje de 110 bytes
(Gp:) En el propio mensaje
(Gp:) enviar (Pdest, msj, 110)
(Gp:) En la llamada

60
Paso de mensajes (Mensajes de longitud fija vs variable)
(Gp:) MINIX 3
(Gp:) typedef struct {
int m_source;
int m_type;
union {
mess_1 m_m1;
mess_2 m_m2;
mess_3 m_m3;
mess_4 m_m4;
mess_5 m_m5;
mess_7 m_m7;
mess_8 m_m8;
} m_u;
} message;
(Gp:) m_source
(Gp:) m_type
(Gp:) m1_i1
(Gp:) m1_i2
(Gp:) m1_i3
(Gp:) m1_p1
(Gp:) m1_p2
(Gp:) m1_p3
(Gp:) m_source
(Gp:) m_type
(Gp:) m2_i1
(Gp:) m2_i2
(Gp:) m2_i3
(Gp:) m2_l1
(Gp:) m2_l2
(Gp:) m2_p1
(Gp:) m_source
(Gp:) m_type
(Gp:) m3_i1
(Gp:) m3_i2
(Gp:) m3_p1
(Gp:) m3_ca1
(Gp:) m_source
(Gp:) m_type
(Gp:) m4_i1
(Gp:) m4_i2
(Gp:) m4_i3
(Gp:) m4_i4
(Gp:) m4_i5
Práctica 4: Nueva llamada SO
Proceso70.if (proceso_vivo(84)
(Gp:) 70
(Gp:) 57
(Gp:) 84
(Gp:) # Llamada 57

61
Paso de mensajes (Capacidad de almacenamiento 0..?)
(Gp:) Ilimitada (?)
(Gp:) Po
(Gp:) Pd
(Gp:) Po
(Gp:) Pd
¡Nunca Bloqueo!
(Gp:) Limitada (8)
(Gp:) Po
(Gp:) Pd
(Gp:) Po
(Gp:) Pd
Hueco ? Sin Bloqueo
¡No hay Hueco!
(Gp:) Bloqueo
Sin Bloqueo
Estado = Lleno
(Gp:) Comunicación Asíncrona
(Gp:) Nula (0)
(Gp:) Po
(Gp:) Pd
¡Siempre Bloqueo!
(Gp:) Po
(Gp:) Pd
Espera a Pd.recibir
(Gp:) Po
(Gp:) Pd
(Gp:) Cita "Rendez-vous"
(Gp:) Po
(Gp:) Pd
(Gp:) Comunicación Síncrona
(Gp:) Po sabe que Pd recibió
(Gp:) ¿Y aquí?

62
(Gp:) Po
(Gp:) Pd
Paso de mensajes (Envío por copia vs referencia)
(Gp:) Escribir
—–
—–
—–
(Gp:) env (Pd, msj)
(Gp:) 1
(Gp:) rec (Po, msj)
(Gp:) 2
¡ 2 copias extra por cada envío/recepción !
(Gp:) Leer
—–
—–
—–
(Gp:) Envío por referencia
(Gp:) Po
(Gp:) Pd
(Gp:) pedirBuffer
(Gp:) Escribir
—–
—–
—–
(Gp:) env (Pd, msj)
(Gp:) rec (Po, msj)
Leer
—–
—–
—–
(Gp:) liberarBuffer
Complejidad pedir/liberar Buffer
¿Y si no hay memoria común?
¿Seguridad?

63
Paso de mensajes (Comunicación Directa)
(Gp:) Indicación explícita
(Gp:) A qué proceso se desea enviar
De qué proceso se desea recibir
(Gp:) Cliente
(Gp:) Servidor
(Gp:) ¿15.731 es primo?
(Gp:) SÍ
repeat repeat
read (msjp.num); recibir ( Pc, &msjp);
enviar (Ps, &msjp); enviar ( Pc,
recibir (Ps, &msjr); respuesta(msjp))
imprimir (msjr.esPrimo) forever
forever
(Gp:) Simétrica
(Gp:) Simétrica

64
Paso de mensajes (Comunicación Directa "Características")
(Gp:) Creación automática del enlace Po Pd
Necesidad de conocer los Pid's de los procesos
De Pi a Pj SÓLO un enlace en cada sentido
(Gp:) Cliente
(Gp:) Servidor
(Gp:) esPrimo?
(Gp:) Hora?
(Gp:) Cliente
(Gp:) Servidor
?
(Gp:) 15.731
(Gp:) 0
(Gp:) 1
(Gp:) Tipo de mensaje
¿Todo resuelto?
(Gp:) Cliente
(Gp:) Servidor
P
P
P
P
P
P
P
H
Un enlace asocia SÓLO a dos procesos

65
Paso de mensajes (Un enlace asocia SÓLO a dos procesos)
(Gp:) C1
(Gp:) C2
(Gp:) S
(Gp:) C1
(Gp:) C2
(Gp:) S
(Gp:) repeat
if recibir (PC1, &msjp ) then
enviar (PC1, respuesta (msjp));
elsif recibir (PC2, &msjp ) then
enviar (PC2, respuesta (msjp));
forever
(Gp:) Servidor
Inanición
Espera Activa
(Gp:) , 1
(Gp:) , 1
(Gp:) Mitigada?
50 Clientes????
! Demasiadas pegas ¡

66
Paso de mensajes (Comunicación Directa Asimétrica)
Mejor admitir un recibir de cualquier proceso (no uno concreto)
(Gp:) C1
(Gp:) C2
(Gp:) S
(Gp:) int recibir (char * msj)
(Gp:) Pid del proceso remitente
(Gp:) int recibir (int * remitente, char * msj)
(Gp:) equivalentes
(Gp:) repeat
remitente := recibir (&msjp);
enviar (remitente, respuesta (msjp));
forever
(Gp:) Servidor
¿Más de un servidor?
(Gp:) int enviar (char * msj)
(Gp:) Pid del proceso que recibió???
(Gp:) C
(Gp:) S1
(Gp:) S2

67
Paso de mensajes (Comunicación Indirecta)
(Gp:) bPeti
(Gp:) PC
(Gp:) PS
(Gp:) 1 ? 1
(Gp:) bPeti
(Gp:) PC
(Gp:) PS1
(Gp:) PSm
(Gp:) 1 ? M
(Gp:) bPeti
(Gp:) PC1
(Gp:) PCn
(Gp:) PS1
(Gp:) PSm
(Gp:) N ? M
¿Quién recibe?
Indeterminismo
Justicia
Integridad
(Gp:) bPeti
(Gp:) PC1
(Gp:) PCn
(Gp:) PS
(Gp:) N ? 1
¿De quién
recibí?
(Gp:) PCn
enviar (buzon, msj) recibir (buzon, msj)
(Gp:) int recibir (buzon, msj)
(Gp:) PCn

68
Paso de mensajes (Comunicación Indirecta)
Los enlaces pueden ser Unidireccionales o Bidireccionales
(Gp:) PC
(Gp:) PS
¿ Problemas ?
(Gp:) PC1
(Gp:) PS
(Gp:) PC2
¿ Y aquí ?
Lo normal Unidireccionales:
(Gp:) bPeti
(Gp:) PC
(Gp:) PS1
(Gp:) PS2
(Gp:) bResp
(Gp:) ¿ Código del Cliente y de los Servidores ?
Lo más general:
(Gp:) B1
(Gp:) P2
(Gp:) P4
(Gp:) P5
(Gp:) B2
(Gp:) P3
(Gp:) P1
Varios Procesos
Varios Buzones
Todo dinámico

69
Paso de mensajes (Comunicación Indirecta)
(Gp:) type Buzones is private;
function Crear (nombreB: Nombres ) return Buzones;
function Conectarse (nombreB: Nombres) return Buzones;
procedure Enviar (b: in out Buzones; msj: Mensajes);
procedure Recibir (b: in out Buzones; msj: out Mensajes);
procedure Destruir (b: in out Buzones);
(Gp:) Un modelo:
(Gp:) Capacidad
(Gp:) *
(Gp:) *
(Gp:) ? Propietario
(Gp:) *
Excepción ? buzonInexistente, …
¡ Problemática Destrucción !
(Gp:) Mensajes en el buzón
Procesos bloqueados
Referencias a buzones destruidos
(Gp:) mqd_t mq_open (const char *name, int oflag, .)
int mq_send (mqd_t mqid, const char *msgptr, size_t msgsz, unsigned msgprio)
ssize_t mq_receive (mqd_t msid, char *msgp, size_t msgsz, unsigne *msgprio)
int mq_close (mqd_t mqid)
(Gp:) POSIX

70
Planificación de Procesos ( Criterios )
Planificar ? Elegir el siguiente Pi a ejecutar
(Gp:) JUSTICIA
EFICIENCIA
RENDIMIENTO
MINIMIZAR TIEMPOS
(Gp:) Criterios
(Gp:) Carga
(Gp:) Sin CPU
(Gp:) Ejecutándose
(Gp:) Pi
(Gp:) Tiempo de Retorno
(Gp:) CPU
(Gp:) Tiempo útil
(Gp:) Tiempo inútil
(Gp:) Tiempo de Espera
¿Tiempo de Respuesta?
(Gp:) Pi
(Gp:) < cr>
Criterios difícilmente alcanzables:
Favorecer Pi ? Perjudicar Pj

71
Planificación de Procesos ( PCPU vs PE/S )
(Gp:) PCPU
(Gp:) PE/S
(Gp:) Periodos largos de CPU
(Gp:) Periodos cortos de CPU
?
¿Cómo reconocerlos?
(Gp:) Abandona voluntariamente la UCP

72
Sistemas Batch
No expulsores o expulsores con un quantum grande
Reducen cambios de contexto y mejoran el rendimiento
Por niveles, Primero en llegar primero en servir FCFS, Más corto el siguiente SJF, Tiempo restante menor SRTN
Sistemas interactivos
Expulsores: evita la monopolización de la CPU
Round-Robin, prioridades, múltiples colas, Más corto el siguiente SPN (envejecimiento)
Sistemas de tiempo real
Monotónico en frecuencia
Deadline más próximo el siguiente
Planificación de Procesos ( Políticas )

73
Planificación de Procesos ( Por niveles )
(Gp:) Planificación a
medio plazo
Memoria
(Gp:) Planificación a
corto plazo CPU
(Gp:) CPU
(Gp:) IT2
(Gp:) T2
(Gp:) T3
(Gp:) T5
(Gp:) T1, T2, T3, T4, T5, T6
(Gp:) S.O.
(Gp:) Entrada al sistema
(Gp:) frecuencia alta
(Gp:) frecuencia baja

74
Planificación de Procesos ( Primero en llegar FCFS )
Sólo cuando un proceso abandona voluntariamente la CPU, la misma se asigna al proceso que lleva más tiempo preparado (FIFO)
D
C
(Gp:) A
(Gp:) B
(Gp:) A
(Gp:) D
(Gp:) B
(Gp:) C
(Gp:) D
(Gp:) B
(Gp:) C
(Gp:) A
(Gp:) E/S
Sencillo, pero ? Ausencia de política
(Gp:) D
(Gp:) C
(Gp:) B
(Gp:) A
(Gp:) 4 4 4 8
(Gp:) D
(Gp:) C
(Gp:) B
(Gp:) A
(Gp:) 8 4 4 4
(Gp:) Tesp
(Gp:) Tret
(Gp:) 9
(Gp:) 14
(Gp:) Tesp
(Gp:) Tret
(Gp:) 6
(Gp:) 11
"Efecto convoy"
(Gp:) {PE/S}n
(Gp:) PUCP
(Gp:) PE/S
(Gp:) {PE/S}n-1
(Gp:) PUCP
(Gp:) E/S
(Gp:) T >>
(Gp:) T <

75
Planificación de Procesos ( Efecto convoy )
PUCP = {10UCP + 2E/S}* PE/S = {1UCP + 2 E/S}*
(Gp:) PUCP
(Gp:) PE/S
CPU al 100%, pero tan sólo 30 unidades de tiempo en E/S
CPU al 100% y además, 55 unidades de tiempo en E/S
(Gp:) PUCP
(Gp:) PE/S
(Gp:) ??

76
Planificación de Procesos ( El más corto primero SJF )
(Gp:) Objetivo: Minimizar Tesp/ret
(Gp:) 8
(Gp:) 5
(Gp:) 4
(Gp:) 3
(Gp:) CPU
3
4
5
8
¿Óptimo?
(Gp:) ¿Dónde esperan los procesos?
(Gp:) CPU
(Gp:) preparados
¿Aplicable SJF en planificación a largo y a corto plazo?
(Gp:) ¿Más corto?
Tiempo total de CPU
Lo declara el usuario
Si engaña ? KILL
(Gp:) ¿Más corto?
(Gp:) Sistemas interactivos
(Gp:) Contraejemplo
(Gp:) 0 1 2 3 4
(Gp:) A(2)
B(4)
(Gp:) C(1)
D(1)
E(1)

77
Variante expulsora del SJF.
Cuando llega un trabajo nuevo, comparar su petición de tiempo
con el tiempo que le queda al actual. Seleccionar el menor.
Favorece a los trabajos nuevos
0 1 2 3 4 5 6 7
A(2)
B(4)
C(1)
D(1)
E(1)
¿Tiempo medio de espera?
Planificación de Procesos ( Tiempo restante menor SRTN )

78
Planificación de Procesos (Round Robin)
"Todos iguales": Turno Rotatorio o Rodajas de Tiempo
A cada Pi que pasa a ejecución se le dá una rodaja "cuanto" de tiempo
(Gp:) La consume totalmente y se le expulsa
(Gp:) Pi
(Gp:) rodaja
(Gp:) La usa parcialmente y abandona voluntariamente la UCP
(Gp:) Pi
(Gp:) sleep, wait, exit
Política FIFO de gestión de la cola de preparados
Dos cuestiones de diseño:
¿Cómo elegir el tamaño de la rodaja?
¿Cómo determinar el fin de rodaja?
Ley del 80%

79
Planificación de Procesos (Round Robin)
¿Cómo elegir el tamaño de la rodaja?
Sea Tcc = 5 mseg (mucho)
Rodaja pequeña 20 mseg => Burocracia del 20%
Rodaja grande 500 mseg => Burocracia del 1%
(Gp:) UCP útil
(Gp:) Respuesta lenta a
usuarios interactivos
(Gp:) ¿Degenera en FCFS?
(Gp:) Mejor
interactividad
(Gp:) Ejemplo: P1, P2, P3 => 24, 3 y 3. Rodajas 4 vs 12 y Tcc = 0,5
P1
P2
P3
P1
(Gp:) P1
(Gp:) P1
(Gp:) P1
(Gp:) P1
(Gp:) 33,5
(Gp:) P1
(Gp:) P2
(Gp:) P3
(Gp:) P1
(Gp:) 31,5
Valores comunes:
20..50 mseg

80
Planificación de Procesos (Round Robin)
¿Cómo determinar el fin de rodaja?
Una interrupción periódica
(Gp:) P1
(Gp:) P2
(Gp:) P3
(Gp:) P4
(Gp:) sleep
(Gp:) ¿Somos justos con P3?
(Gp:) ¿viable?
F(int) en 68901 [1µseg..20mseg]
Dar 2 rodajas
Resetear interrupción
Sumar ticks de una interrupción más frecuente
(Gp:) P1
(Gp:) P2
(Gp:) sleep
(Gp:) P3
(Gp:) P4

81
Planificación de Procesos (Prioridades)
"Unos más importantes que otros": Cada Pi prioridad explícita
(Gp:) 0 N
N 0
(Gp:) mín
(Gp:) máx
(Gp:) expulsora
(Gp:) P3
(Gp:) P7
(Gp:) P1
UCP siempre ejecuta Pi más prioritario
UCP libre ? ejecutar Pi más prioritario
Igualdad de prioridad ? FCFS, Round Robin
Prioridades estáticas vs dinámicas
(Gp:) Sencillo pero inanición
(Gp:) P3
(Gp:) P7
(Gp:) P1
(Gp:) P9
(Gp:) ¿ tiempo real ?
(Gp:) no expulsora
(Gp:) P3
(Gp:) P7
(Gp:) P1

82
Planificación de Procesos (Prioridades dinámicas)
Evitar la inanición:
Disminuir la prioridad a medida que se usa la UCP
Aumentar la prioridad si se está tiempo en preparados
¿ Favorece a los trabajos cortos ?
(Gp:) PE/S vs PUCP
Favorece a los Pi ligados a E/S
¿Cuáles son PE/S?
¿Todo el tiempo será PE/S?
(Gp:) PE/S aquellos que usen una parte menor de la rodaja de UCP
Ejemplo con rodajas de 100 mseg:
P1 usa 2 mseg de UCP ? PE/S
P2 usa 25 mseg de UCP ? PUCP
(Gp:) Prio (P1) = 100/2 = 50
Prio (P2) = 100/25 = 4
¿Rango de prioridades [0..N]?
(Gp:) Estáticas muy bajo ? 16
Dinámicas muy variable

83
Planificación de Procesos (Múltiples colas)
"Mezcla de políticas": Cada Pi asociado a una cola de forma estática
(Gp:) Prioridad
(Gp:) 3
(Gp:) 2
(Gp:) 1
(Gp:) 0
(Gp:) FCFS
(Gp:) Round
Robin
(Gp:) Quantum
(Gp:) 4
(Gp:) 8
(Gp:) 16
Dos elecciones:
Seleccionar cola
Seleccionar proceso dentro de la cola
(Gp:) ¿Expulsora?

84
Planificación de Procesos (Múltiples colas realimentadas)
"Mezcla de políticas": Cada Pi asociado a una cola de forma dinámica
Menos Cambios de Contexto
(Gp:) Prioridad
(Gp:) 4
(Gp:) 3
(Gp:) 2
(Gp:) 1
(Gp:) 0
(Gp:) 1
(Gp:) + Rodajas Variables
2
4
8
16
Rodajas para Pi ? 1, 2, 4, 8, 16
Favorecer selectivamente PE/S
(Gp:) Prioridad
(Gp:) 3 Terminal
2 E/S
1 Rodaja corta
0 Rodaja larga
Consumir rodajas:
Bajar de prioridad

85
Planificación de Procesos (MINIX 3)
(Gp:) /usr/src/kernel/proc.h
(Gp:) Pi
(Gp:) SI consumió su rodaja
Nueva rodaja
Prioridad++ ¡Menor!
Encolar_Al_Final
SINO
Encolar_Al_Principio
(Gp:) sched
(Gp:) Preparados
(Gp:) MaxPrioridad
(Gp:) MinPrioridad
(Gp:) RoundRobin
(Gp:) proc[log].p_nextready

86
Planificación de Procesos ( Pi más corto siguiente SPN )
(Gp:) CPU
(Gp:) preparados
(Gp:) ¿Más corto?
(Gp:) ¿Más corto?
(Gp:) SJF
(Gp:) SPN
(Gp:) Tiempo de próxima posesión de UCP
?
(Gp:) ¿Predicción? (?i) ?
?i+1 = F (ti, ?i)
?i+1 = ? ti + (1- ?) ?i y ? = 1/2
Predicción
(Gp:) ?i ?
(Gp:) ti ?
10
6
8
4
(Gp:) 6
(Gp:) 6
(Gp:) 6
(Gp:) 4
(Gp:) 5
(Gp:) 13
(Gp:) 9
(Gp:) 13
(Gp:) 11
(Gp:) 13
(Gp:) 12

87
Dado
m eventos periódicos
evento i ocurre en el periodo Pi y precisa Ci segundos
El sistema es planificable si
Hard real time vs Soft real time
Eventos: periódicos vs aperiódicos
(Leer las secciones 7.4.2, 7.4.3 y 7.4.4)
Planificación de Procesos ( Sistemas de Tiempo Real )

88
Separar qué se puede hacer de cómo hacerlo
Un proceso puede saber cuáles de sus threads hijos son los más importantes y asignarles prioridad
Algoritmo de planificación parametrizado
Mecanismo en el kernel
Los procesos de usuario ponen el valor de los parámetros
Los procesos de usuario indican la política
Planificación de Procesos ( Política vs Mecanismo )
pthread_attr_setschedpolicy(.) => FIFO, RR, OTHERS

89
Quantum por proceso de 50 mseg
Cada thread ejecuta 5 mseg de ráfaga de CPU
Planificación de Threads ( Espacio de usuario )

90
Planificación de Threads ( Espacio de kernel )
Quantum por proceso de 50 mseg
Cada thread ejecuta 5 mseg de ráfaga de CPU

91
Sistemas multiprocesador
(Gp:) µP1
(Gp:) µP2
(Gp:) µP3
(Gp:) µP4
Cada µP su cola
(Gp:) Peligro de carga desequilibrada
(Gp:) µP1
(Gp:) µP2
(Gp:) µP3
(Gp:) µP4
¡ Ojo ! ? Spin Lock
Planificar ? ¿Qué thread? ¿En qué núcleo?
Tiempo compartido Threads independientes Cola única
(Gp:) No escalable con aumento núcleos
(Gp:) Espera activa si FR ? Spin Lock
(Gp:) ¡Estoy en RC! ? Alarga rodaja
(Gp:) Problemática caches ? Afinidad

92
Sistemas multiprocesador
Ordenando 128.000 claves "burbuja" en Intel Core 2 Quad Q6600 2,46GHz
(Gp:) µP0
(Gp:) 4MB L2
(Gp:) µP1
(Gp:) µP2
(Gp:) 4MB L2
(Gp:) µP3
sched_setaffinity

93
Sistemas multiprocesador
Espacio compartido Threads cooperantes Apropiarse {µP}n
(Gp:) Núcleo ocioso cuando Pi.bloqueado
(Gp:) Sin multiprogramación ? ¡Menos burocracia!
(Gp:) Sin "n" núcleos libres no me ejecuto
(Gp:) Servidor Web con {threads} variable

94
Sistemas multiprocesador
Planificar por pandillas Threads cooperantes Tiempo/Espacio
(Gp:) Espacio compartido
(Gp:) Tiempo compartido
 Página anterior Página anterior | Volver al principio del trabajo | Página siguiente  |